Hello Community!
Recently, I needed to retrieve text content from a TXT file for further processing. I struggled to find a solution until some developers suggested the simplest method—I’m sharing it here with you.
The best option is to use this straightforward code in a JavaScript node:
import fs from 'fs';
export default async function run({ execution_id, input, data, store, db }) {
const filePath = data["{{10.result.file.content}}"];
return {
fileContent: fs.readFileSync(filePath, { encoding: 'utf-8' })
};
}
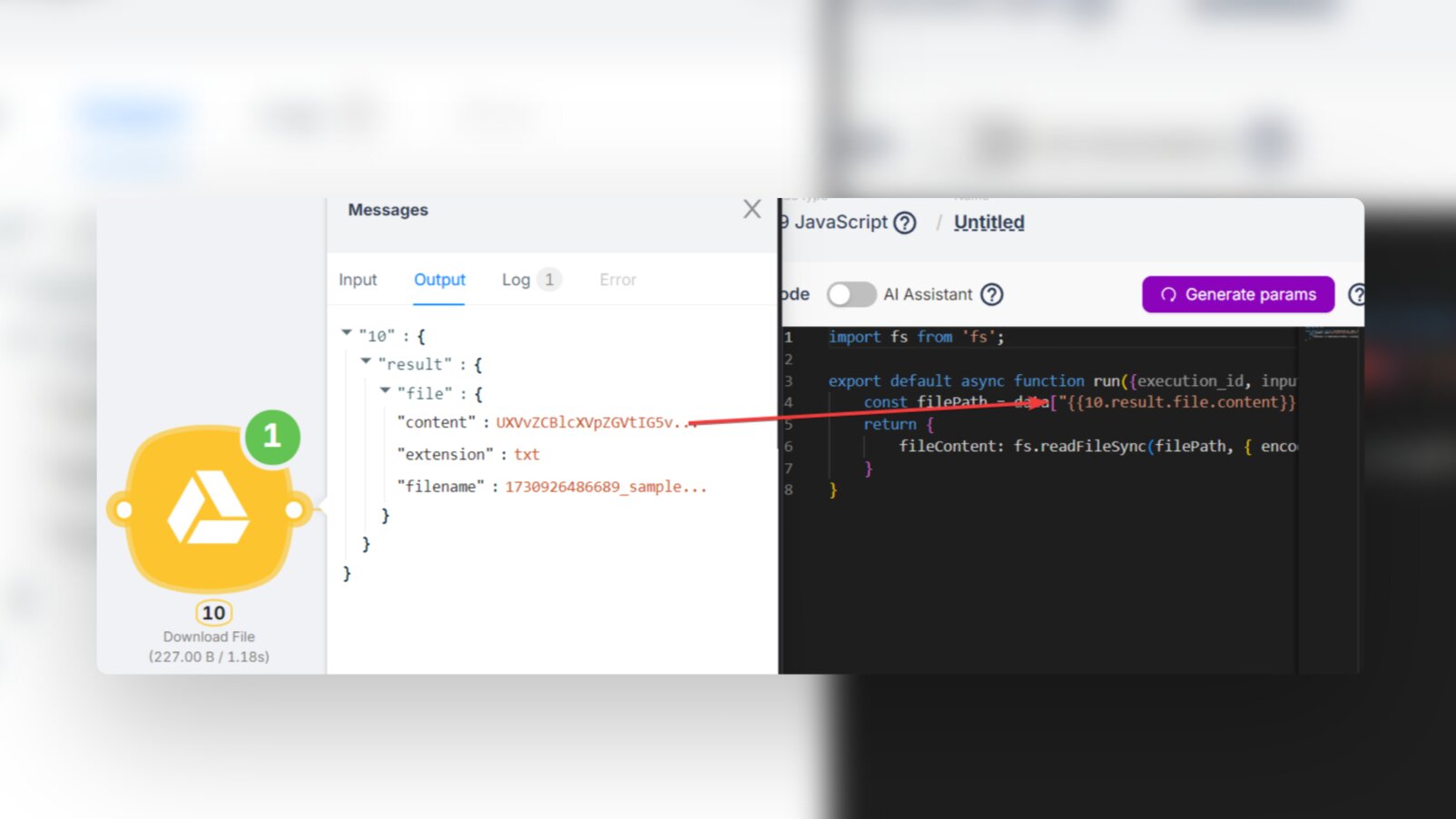
Here, replace the variable {{10.result.file.content}} with the “content” of your binary file. This method works perfectly—you get the text as a string, ready for further use!

Inspired by this success, I took it a step further and applied the same approach to extract content from other types of files.
For example, in one of my scenarios, I used a plug-n-play “converter” node to convert a PDF invoice into TXT format, which allowed me to retrieve the text content effortlessly. The result was surprisingly readable and perfectly suited for further processing in GPT.

For example, here’s how the original PDF invoice was interpreted by GPT.
Accordingly, nothing now prevents you from structuring everything to suit your needs and obtaining any necessary output data for automations.
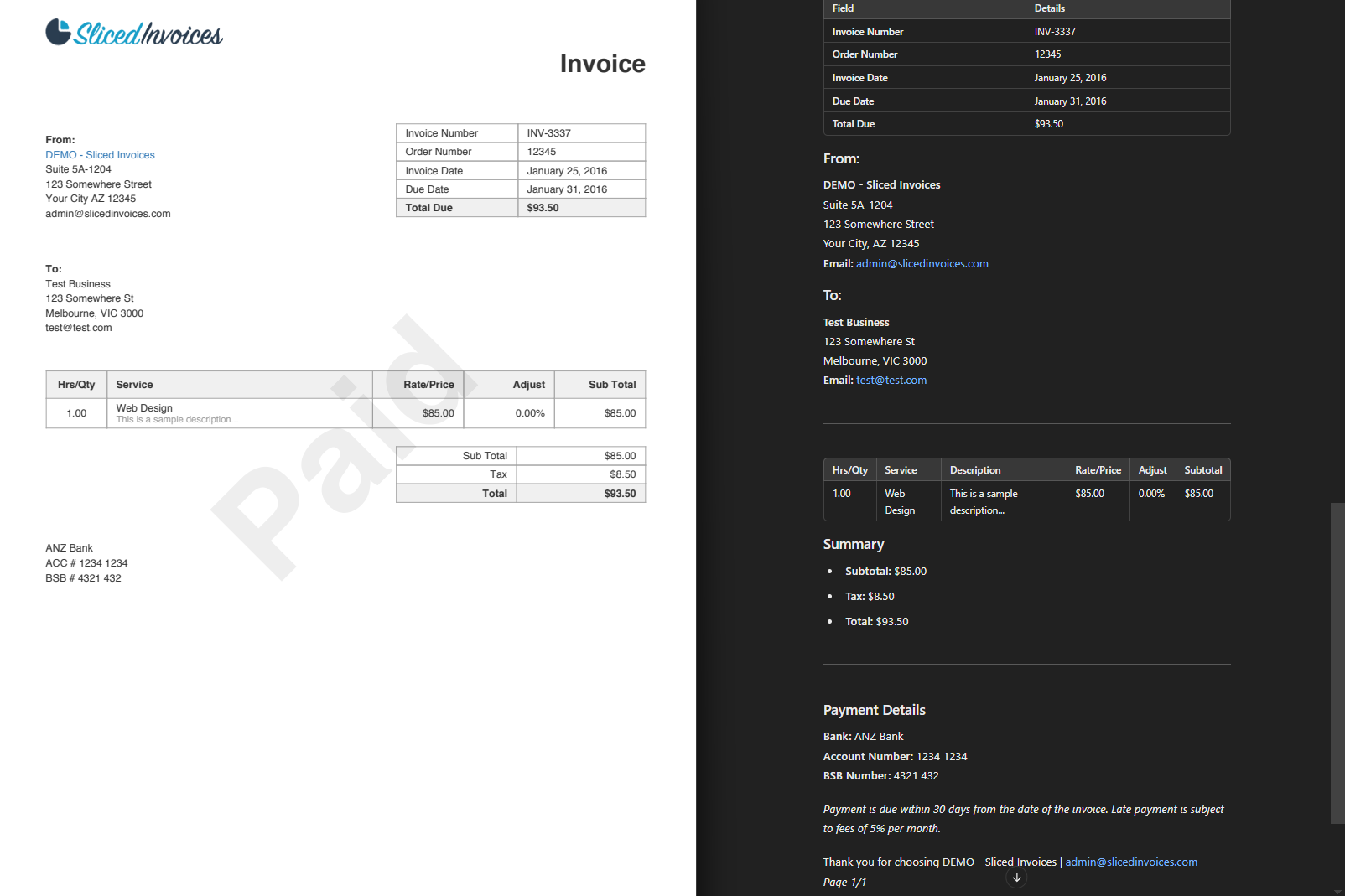
And considering that this method didn’t require connecting to any external APIs and cost only around 3 cents (in equivalent credits), it’s a pretty good solution!
I hope this helps someone out there!
Btw, I’ll soon publish a template and description of a scenario for automating invoice processing and data structuring. Stay tuned!