Many users want to start web scraping but feel overwhelmed when faced with a code window in the Headless Browser node. Let me ease your concerns and show you how to extract basic data from the websites you need.
This isn’t a full tutorial on the Headless Browser—just a simple first step to get you started. Start small!
I’ve created a simple use case for you. By providing just the URL you need, you can extract all the necessary data from the page using a simple integration of the Headless Browser and ChatGPT, which you can implement right away!
Let’s Dive into the Scenario
Input Data
The “Run Once” trigger exists here solely for testing purposes, but you can easily replace it with, for example, a trigger for a new row in a database table.
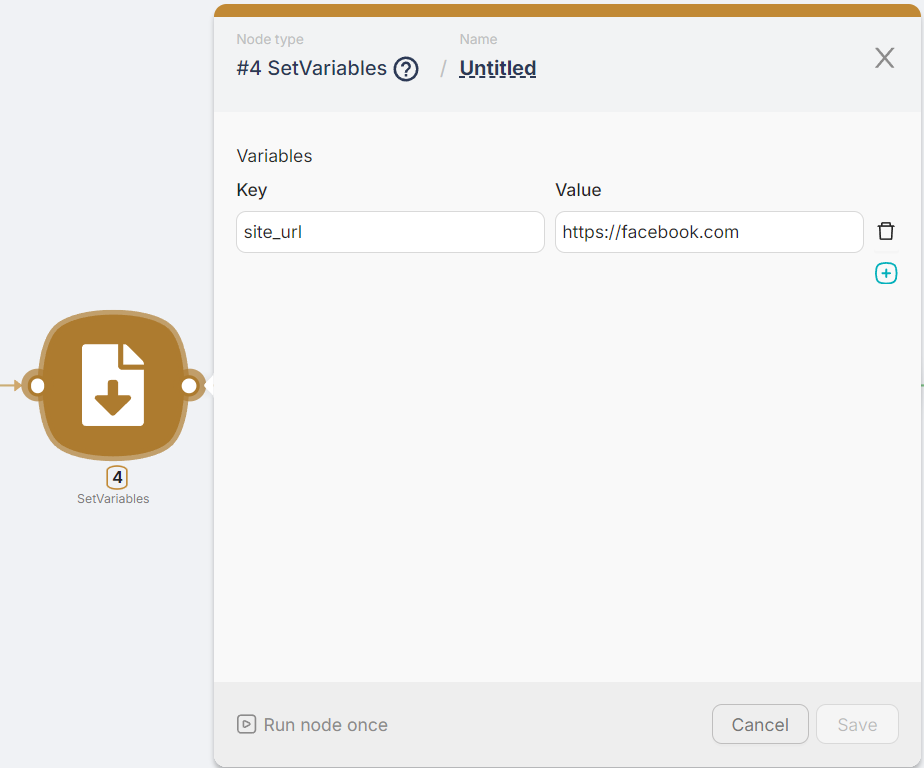
In the Set Variables node, we specify the desired URL, which will be passed to the Headless Browser
Website Scraping
Now for the most interesting part—the Headless Browser!
Our Headless Browser is built on the Puppeteer library, supporting nearly its entire functionality. All we need to do is place the required code into its editor window.
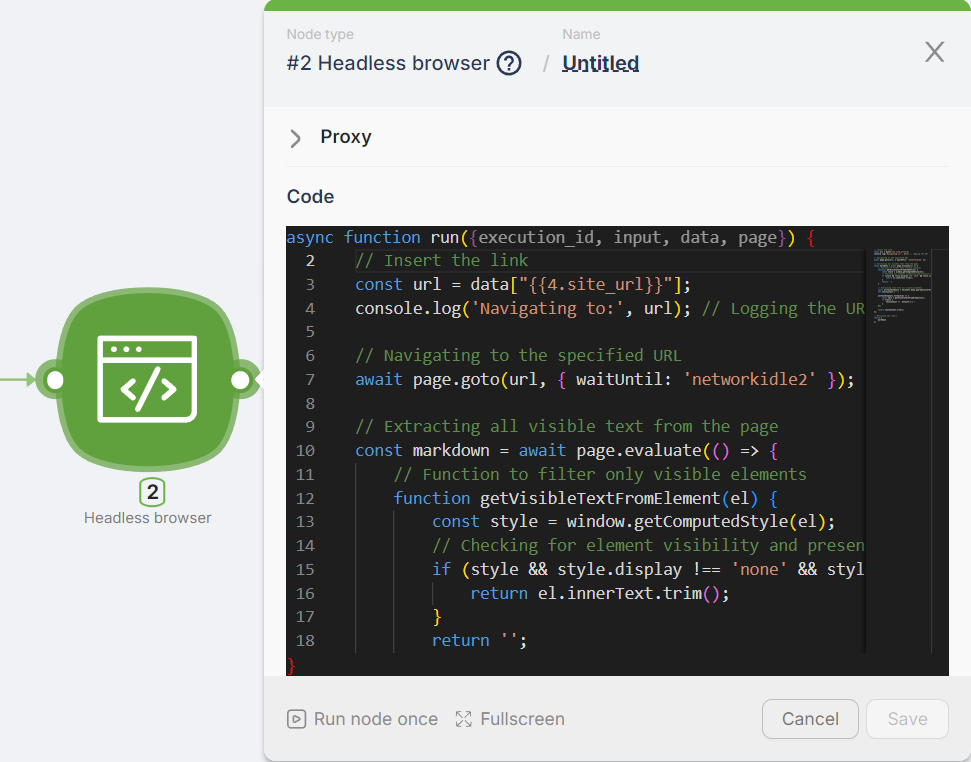
Don’t worry! No need to fully understand how it works—just copy my code and you’re good to go!
I’ve used this script for multiple cases, and it covers most of my basic scraping needs:
// Insert the link
const url = data["{{4.site_url}}"];
console.log('Navigating to:', url); // Logging the URL
// Navigating to the specified URL
await page.goto(url, { waitUntil: 'networkidle2' });
// Extracting all visible text from the page
const markdown = await page.evaluate(() => {
// Function to filter only visible elements
function getVisibleTextFromElement(el) {
const style = window.getComputedStyle(el);
// Checking for element visibility and presence of text
if (style && style.display !== 'none' && style.visibility !== 'hidden' && el.innerText) {
return el.innerText.trim();
}
return '';
}
// Extracting text from all visible elements
const allTextElements = document.body.querySelectorAll('*');
let textContent = '';
allTextElements.forEach(el => {
const text = getVisibleTextFromElement(el);
if (text) {
textContent += `${text}\n\n`;
}
});
return textContent.trim();
});
// Returning the result
return {
markdown
};
The output is all the visible text from the website, neatly formatted in Markdown.
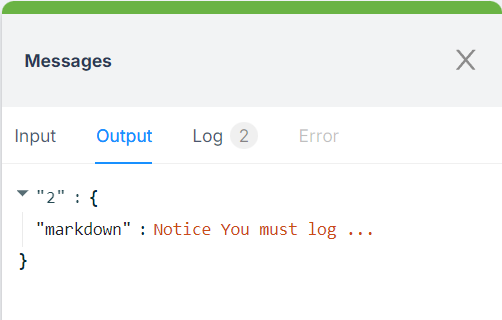
However, this raw text often includes unnecessary information. The next step is to clean it up and focus on the most important details.
Data Cleanup
This is where our AI assistant comes into play, customized to meet your specific needs—whether it’s extracting website content, collecting headers, or even generating a creative summary. After all, it’s AI—you’ll get exactly what you need!

For my example, the setup is straightforward ![]() .
.
The final output is a neatly organized set of the essential details from the page.
Next, we pass this output into a custom JavaScript node. To create it, simply ask our JavaScript to “Extract JSON from ChatGPT’s response”—a task it handles effortlessly!
And here’s what we get as the output—a ready-to-use JSON containing all the requested information.
Impressive, isn’t it?
Important Note:
If you want to analyze multiple websites using the same template, include a detailed example of the desired output format (preferably as a JSON example) in your prompt. This ensures consistent, structured results every time.
Potential Use Cases
- Monitor website changes
- Create posts based on site updates
- Track keywords you’re interested in
- Analyze client websites for valuable insights
And so much more—easily achievable with this Latenode scenario!
The template for this scenario will be added soon, so stay tuned.
Ready to get started?
Join Latenode, and you too will be able to create automations of any complexity without a hitch.
